HonestAI
Software Engineer - develop product, server/infra engineering 2024. Dec ~ 2026. Mar
해당 페이지는 HonestAI에 근무하면서 마주했던 문제들과 고민, 해결방법 및 결과등을 상세하게 서술한 문서입니다.
맡은 업무와 경험들은 아래 Resume에, 자세한 내용은 세 가지로 추려 서술했습니다.
Resume
Server
- 저축은행 온라인 연계투자 시스템 개발/운영 담당
- 저축은행 중앙회, NICE/KCB, 신한은행, 금융결제원, Toss, KakaoPay등 외부 API 시스템 연동
- 대출 시스템 트래픽 1,000건 → 50만건 성능 테스트 및 인프라 증설 지원, Netty 서버 병목 해결 (jstack, netty)
- 연계투자 연동 시스템 장애 알림 시스템 구축으로 장애 감지율 향상 (40% → 90%)
- 연계투자 투자질의 → 확정 → 입금 → 집행 사이클 시스템 장애 대응 프로세스 구축 (Read-Time 15m → 30s)
- NICE 신용 평가 배치 조회 시스템 데이터 100MB → 1GB 확장에 따른 회선 대역폭 포화 대응 데이터 전송 트래픽 제어
- 전문 통신 서버 TCP 튜닝, 레이턴시 개선 (커넥션 재활용 socket pool, nagle 알고리즘 비활성화등 000ms단위 개선)
Infra
- JVM, K8s 시스템 Prometheus, Grafana, Micrometer 기반 Monitoring & Observability 구축
- Loki, Grafana 대시보드 기반 로그 Observability 구축
- Athena 로그 테이블 Partition Projection 기반 재설계로 최적화 쿼리 시간 개선 (로그 조회 4~5m → 1~4s 단축)
- 레거시 시스템 JVM 기반 Observability 구축(jmx-prometheus) 및 튜닝 (jcmd, jstack, jmap etc..)
- 결산 배치 Full GC Hang 상황 감지 이후 메모리 조정 및 결산 배치 Hang 감지 알림(alert manager) 시스템 개발
- 플랫폼 서버 G1GC 전환 (P99 2~3s → 0.4s 단축) 및 OpenJDK 8 최적화 검증, 비교 성능 테스트, 모니터링
- Gradle 프로젝트 빌드 병렬/캐시 및 데몬 힙사이즈 조정, CI flow 개선으로 빌드타임 개선 (20m → 1~3m)
- Micrometer 기반 Domain Error 집계 개발 장애 빈도, 우선순위 산출에 기여함 (알림 Slack API 토큰 절약에도 기여)
- 코어뱅킹 Task DB lock timewait, deadlock 모니터링 및 시스템 개선
Finance
- 어니스트펀드 코어뱅킹 시스템 채권과 저축은행 중앙회 연계투자 채권 원장을 동기화하는 작업을 지원함
- 정규 상환일 상환 관련 테스크 운영 관리, 특수 실현 및 기한이익상실 관련 채권들에 관한 스케쥴 관리 작업을 지원
- 신용정보원, NICE/KCB, 금융결제원 채권 상태 동기화 및 동시대출 등록 시스템 관리 및 검증 시스템 관리
- 대출 신청부터 기표까지 프로세스 시스템 관리 및 신용평가모형(R-Clips) 결과값 기반 자동 대출 시스템 개발
전문통신서버(CB사 신용평점 제공기관 NICE/KCB 연동 시스템) Proxy 성능 개선기
본문에 들어가기 앞서 이 차트는 저희 어니스트펀드 BaaS 모델의 연계대출부터 투자까지의 시스템 구조도 입니다.
이 차트를 참고하시면 본문 내용의 이해가 좀 더 수월해질 수 있습니다.
Architecture Diagram
graph TD
classDef b2c fill:#1a1a2e,stroke:#555,stroke-width:1px,color:#ccc;
classDef sync fill:#0d1b2a,stroke:#1e88e5,stroke-width:1px,color:#90caf9;
classDef async fill:#1a1500,stroke:#ffa000,stroke-width:1px,color:#ffe082;
classDef internal fill:#0a1f0a,stroke:#43a047,stroke-width:1px,color:#a5d6a7;
classDef external fill:#1f0a0a,stroke:#e53935,stroke-width:1px,color:#ef9a9a;
classDef shared fill:#1a0a2e,stroke:#8e24aa,stroke-width:1px,color:#ce93d8;
subgraph B2C_Channel ["제휴 채널"]
Toss["Toss / KakaoPay / Finda / Banksalad etc.."]:::b2c
end
subgraph Sync_Zone ["빠른 접수 구간 - Sync"]
ELP["External-Loan-Platform-Api"]:::sync
end
MQ[("Message Queue")]:::async
subgraph Async_Zone ["외부 플랫폼 연계 대출 비동기 컨슈머"]
Consumer{"External-Consumer-App"}:::async
end
subgraph Internal_Targets ["내부 핵심 시스템"]
HF["HF (코어뱅킹 / 대출원장)"]:::internal
RClips["RClips 신용평가모형"]:::internal
OtherApps["사내 기타 앱 (Admin 등)"]:::internal
end
subgraph External_Adapters ["외부 기관 어댑터"]
SBApp["SavingsBankApp"]:::external
SBCentral[("저축은행 중앙회")]:::external
Shinhan[("신한은행")]:::external
end
subgraph Shared_Gateway ["공통 대외망 게이트웨이 (Shared)"]
Proxy["Nice-Proxy (Netty)"]:::shared
CB[("NICE / KCB")]:::external
end
Toss -- "1. 심사/연계 요청" --> ELP
ELP -. "2. 접수 (200 OK)" .-> Toss
ELP -- "3. 이벤트 발행" --> MQ
MQ -- "4. 이벤트 소비" --> Consumer
Consumer -- "모형 실행" --> RClips
Consumer -- "대출/투자/결제 로직 위임" --> HF
HF -- "연계투자 요청" --> SBApp
SBApp -- "망연계 규격 통신" --> SBCentral
HF -- "계좌/결제 연동" --> Shinhan
Consumer -- "신용조회 (JSON)" --> Proxy
ELP -. "필요시 직접 조회" .-> Proxy
HF -. "필요시 직접 조회" .-> Proxy
OtherApps -. "공통 활용" .-> Proxy
Proxy -- "TCP 전문 통신" --> CB
Consumer -. "최종 결과 Callback" .-> Toss
Summary
As-Is
- Event Loop 스레드에서 blocking call (socketRead0) 직접 호출
- String += 연산으로 요청당 임시 객체 14,000개 생성
- Young GC 초당 5~10회, Full GC 15,364회 발생
- Old Generation 사용률 91~94% 포화
- 전문 잘림 이슈 (flush 전 close)
- Short-lived Connection으로 TIME_WAIT 소켓 누적
- Nagle 알고리즘으로 대용량 전문 전송 지연 (~40ms 추가)
To-Be
- Blocking call을 전용 스레드풀로 오프로딩, 이후 channelRead() + ByteBuf 구조로 전환
- StringBuilder 전환으로 요청당 임시 객체 1개
- Young GC 빈도 58% 감소, Full GC 100% 제거
- GC 오버헤드 96% 감소, Old Gen 압박 대폭 해소
- ChannelFutureListener 적용으로 전문 잘림 해결
- Persistent Connection 전환으로 TIME_WAIT 제거, 3-way handshake 레이턴시 ~1.5ms 절감
- Nagle 비활성화(TCP_NODELAY)로 전문 전송 지연 ~40ms 절감
Nice-Proxy
nice-proxy라고 불리는 네티 기반의 프록시 서버가 존재합니다.
nice라는 신용평점제공 기관의 서버 시스템은 현재 4Mbps의 대역폭과 100개의 세션까지를 제공해주고 있었습니다.
그리고 아래와 같은 조건/문제들이 존재했습니다.
- nice 전문 통신 응답시간은 0.5~3s정도고 최악의 경우에는 10 ~ 60s까지 튈때도 있습니다.
- NICE의 평균 전문사이즈는 14KB ~ 32KB정도로 무거운 사이즈를 자랑한다.
- 세션이 100개다 보니(심지어 이것도 증설해준거) 그 이상의 요청이 들어오게 되면, 실패처리 되어버립니다.
NICE 전문 통신은 연계대출 프로세스를 진행하기위해서 무조건 필요한 데이터기 때문에 반드시 호출 후에 값을 받아내야합니다.
즉 NICE 서버 성능에 우리 어니스트펀드 서버 자체가 결합되어있다는 문제가 발생하게 됩니다.
그래서 아래와 같은 문제 해결과 이점을 위해 netty 기반의 nice-proxy가 배치되었습니다.
- 외부 금융/B2B망의 엄격한 동시 접속 세션 제한(IP당 N개)을 준수하면서도, 내부의 수많은 동시 트래픽을 병목 없이 라우팅 필요
- 네티의 유연한 파이프라인 구조 (ChannelPipeline): 데이터가 흐르는 통로에 암복호화, 인코딩, 디코딩, 비즈니스 로직 등의 스트림 처리 단계를 체인(Chain) 형태로 깔끔하게 모듈화하여 배치
- 고성능 바이트 조작 (ByteBuf & Zero-copy): 자체적인 메모리 버퍼 객체를 통해 거대한 바이트 스트림을 물리적인 메모리 복사 없이(Zero-copy) 자르고 붙일 수 있어 GC 부하를 최소화
연계대출(투자)라는 무거운 콜에 대해 예측/발생 트래픽 발전은 200TPS까지로 확인되었습니다. 100개의 세션 고갈은 반드시 발생할것이고 그에 따라 장애 연쇄를 막기위해 배치된것입니다.
그러던 어느날 올라온 슬랙

nice event loop thread의 수를 증설한다는 문구를 확인.
발생했던 현상은
- nice가 아닌 nice-proxy 서버의 이벤트 루프 스레드가 밀림.
- nice-proxy 서버 자체가 느림
이 두가지 였습니다. thread가 밀린다는 말에 스레드덤프를 먼저 확인했고, (별도의 observability가 없을때라 직접 접속해 jstack, jstat, jmap등으로 모니터링)
다음의 문제들을 확인했습니다.
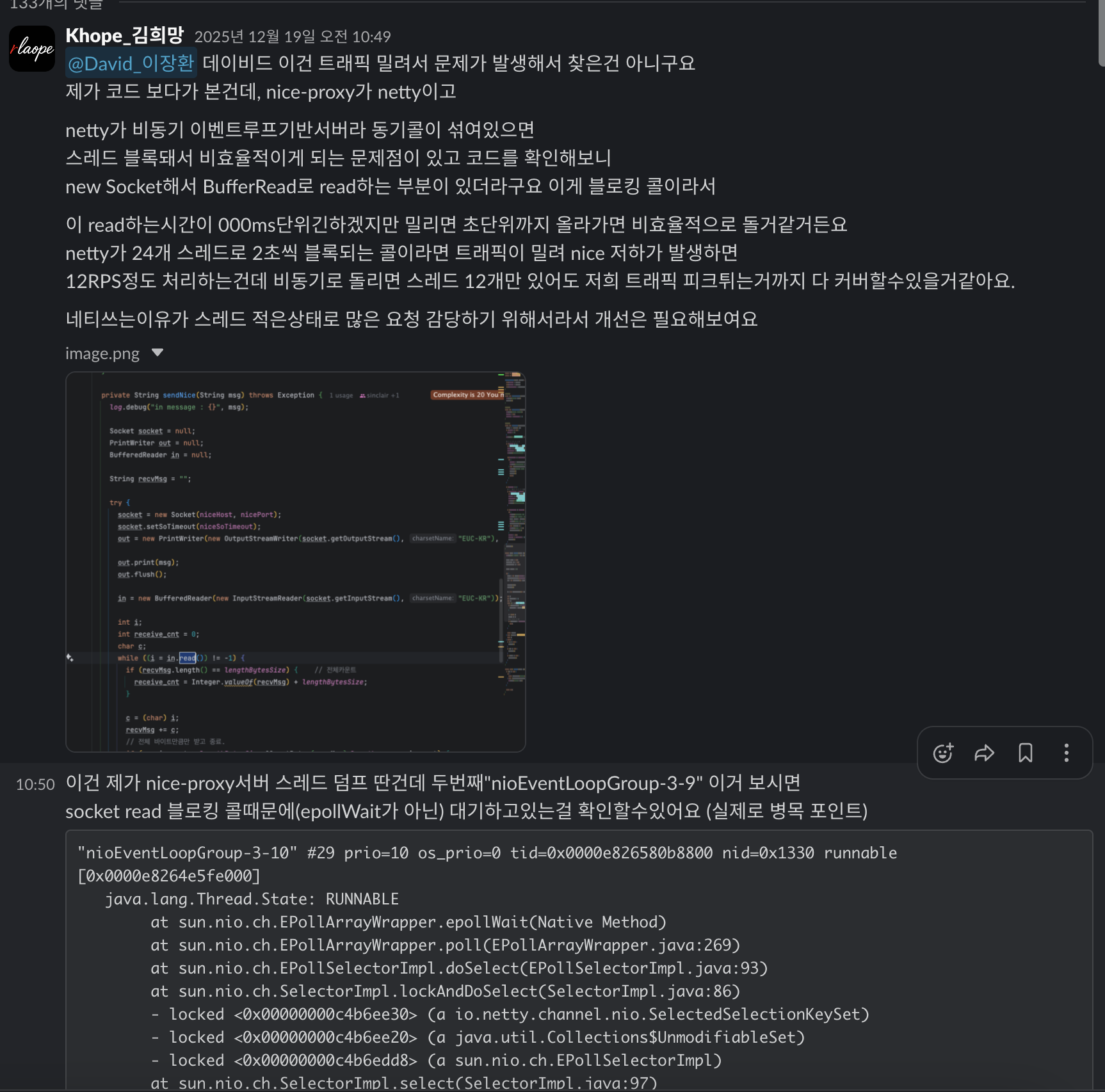
- (치명) blocking call (socketRead0)가 event loop 스레드에서 호출되는것을 확인
- (치명) string += 연산을 통한 힙메모리 복사비용 낭비로인한 FULL GC 비율이 90% 이상
2번 문제에 관한 정의는
| 지표 | 값 | 설명 |
|---|---|---|
| YGC (Young GC 횟수) | 41,330,984회 | 4천만 번 발생 |
| YGCT (Young GC 총 시간) | 35,150초 | 약 9.7시간 GC에 소요 |
| FGC (Full GC 횟수) | 15,364회 | 1.5만 번 발생 |
| Old Generation 사용률 | 91~94% | 거의 포화 상태 |
| 실시간 YGC 빈도 | 초당 5~10회 | 매우 빈번 |
별도로 Nice-Proxy에 관한 별도 문제들을 전반적으로 더 분석해 아래와 같은 문제들도 확인했습니다.
- (치명) 전문이 잘리게 되는 이슈 (channelFutureListener 미사용으로 os에 write전에(flush) close해버리는 문제)
- Backpressure, Circuit Breaker 메커니즘 존재안함.
- Persistence Connection 방식으로 동작 안해 TIME_WAIT 상태 소켓 비율이 높음 (3-way-handshake latency)
- Nagle 알고리즘 활성화 되어있음 (nice 전문사이즈가 커 비효율적으로 동작할 수 있음. 두 번이상의 콜로 처리될 수 있어서. mss가 1460이면 커버 다 안됨)
처리량에 대한 개선
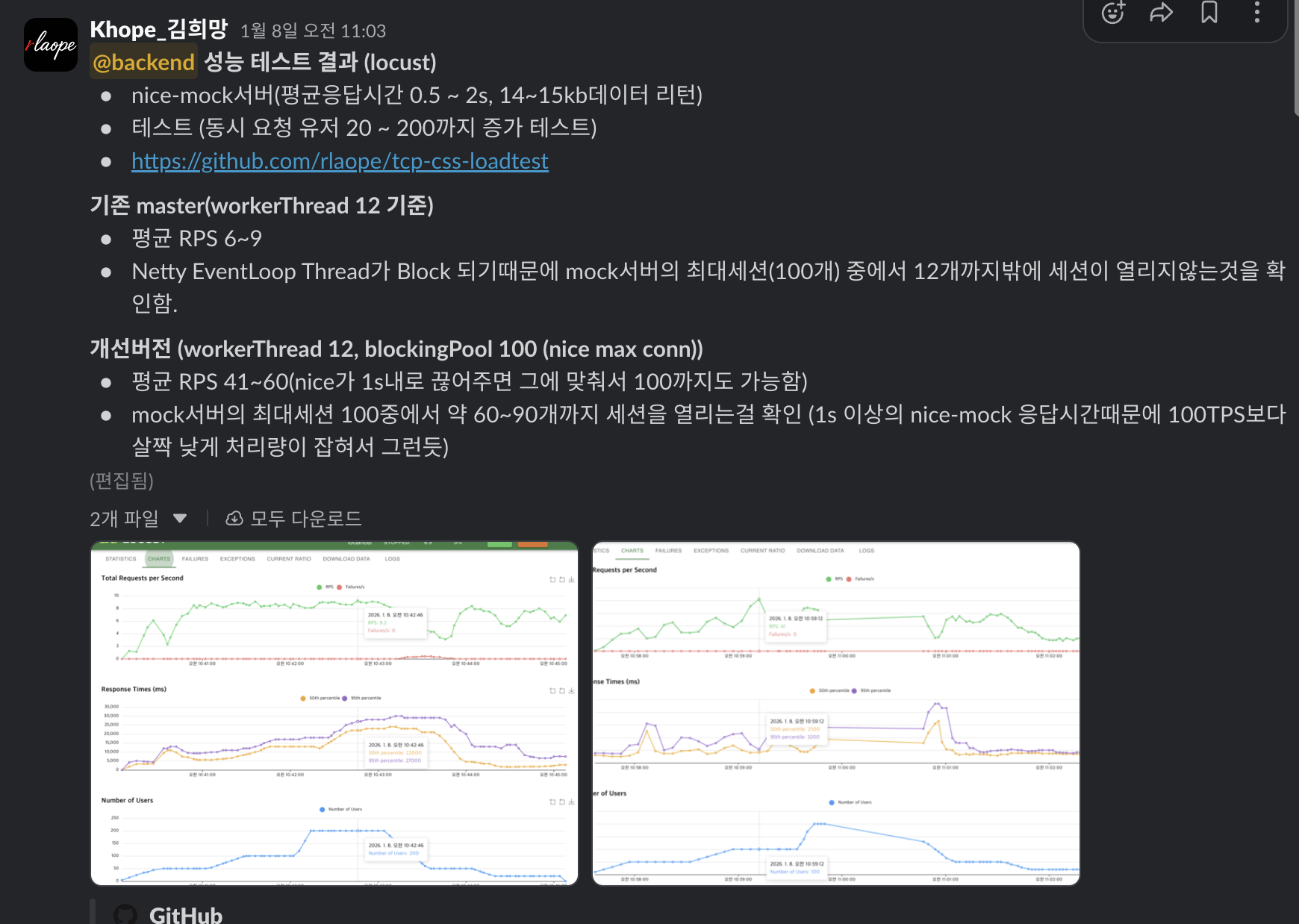
1차적으로 blocking call을 별도 스레드로 오프로딩
- 스레드풀을 100개로 두어 nice 세션을 넘지 않도록 했지만, 이는 아직 궁여지책. 이벤트 루프 스레드가 밀리진 않지만, 어찌되었든 100개의 스레드로 제약이 걸려버려. netty를 쓰는 이유가 없어짐
- 향후 nice증설도 진행했고 channelRead()로 bytebuf를 통해 전문을 받는구조로 변경해두었음. nice 커넥션의 값만 넘치않도록 semaphore 조정
String 연산은 삭제 후 Builder를 사용하도록, 불필요한 복사를 통해 FullGC가 계속해서 발생하는것을 모니터링을 통해 확인후 수정작업 진행함
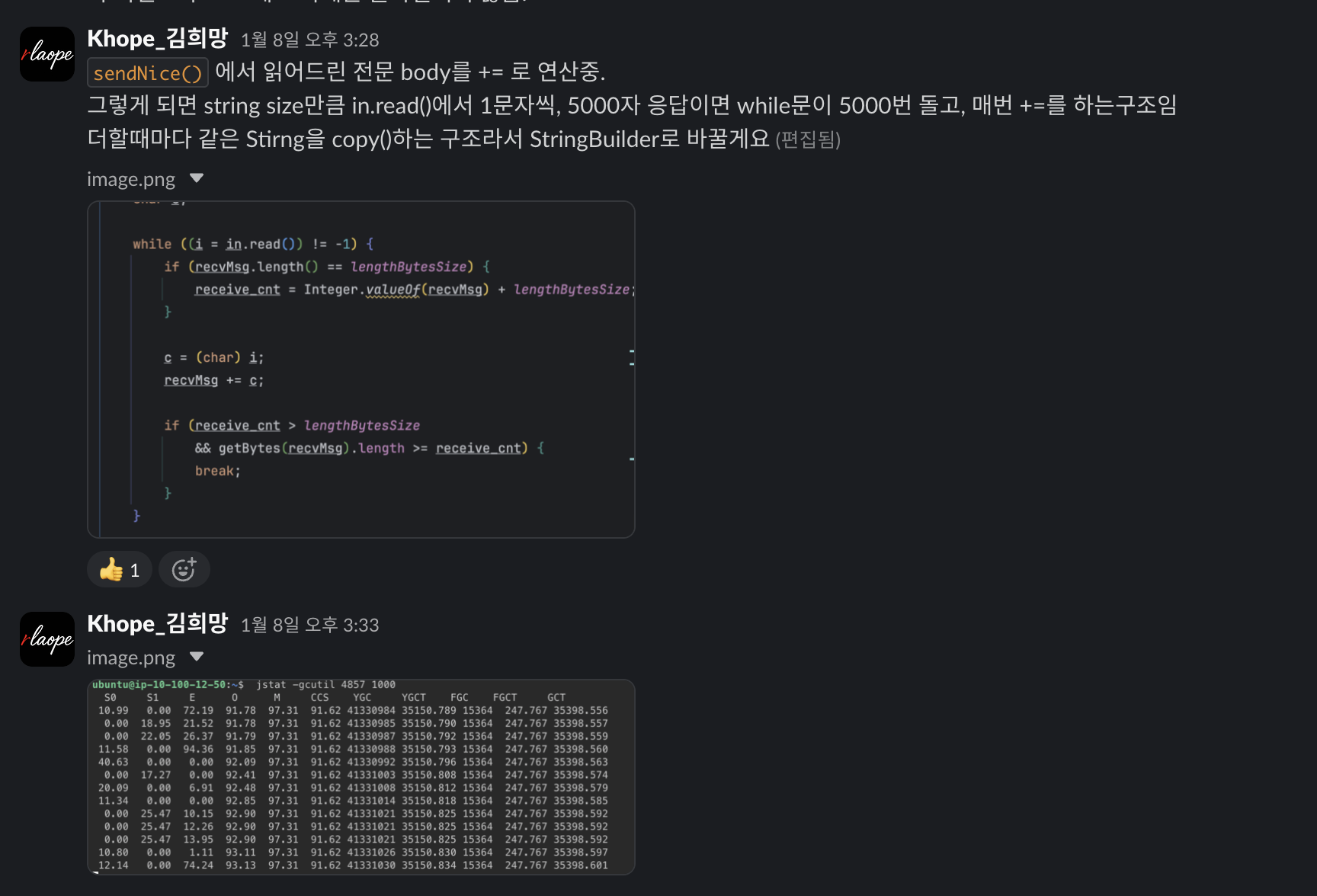
| 지표 | 개선 전 | 개선 후 (예상) |
|---|---|---|
| YGC 빈도 | 초당 5~10회 | 초당 0~1회 |
| 요청당 임시 객체 | 14,000개 | 1개 |
| GC로 인한 지연 | 수십~수백 ms | 최소화 |
| Old Gen 압박 | 91~94% | 대폭 감소 |
- Young GC 빈도 58% 감소
- Young GC 시간 72% 감소
- Full GC 100% 제거
- GC 오버헤드 96% 감소
벤치마크 및 테스트(locust)도 진행 (아래 사진은 blocking call 오프로딩 기준)
Circuit Breaker
NICE 응답시간이 5s 이상 걸리면 선형적으로 증가하다가 60s가 넘어 뻗는 패턴들이 빈번했다. 이 상태에서 요청을 계속 보내봤자 세션만 잡아먹고 뒤에 대기중인 요청들까지 연쇄적으로 밀리게 된다.
그래서 서킷브레이커를 추가했다. 빠른 실패 처리를 통해 이미 뻗은 상태의 NICE에 무의미한 요청을 보내지 않고, 후속 요청들이 불필요하게 대기하는것을 방지했다. 세션이 100개 밖에 없는 상황에서 하나의 느린 요청이 세션을 점유하고 있으면 다른 정상 요청까지 실패하게 되기 때문에 서킷은 필수였다.
향후 개선 (Network, Observability)
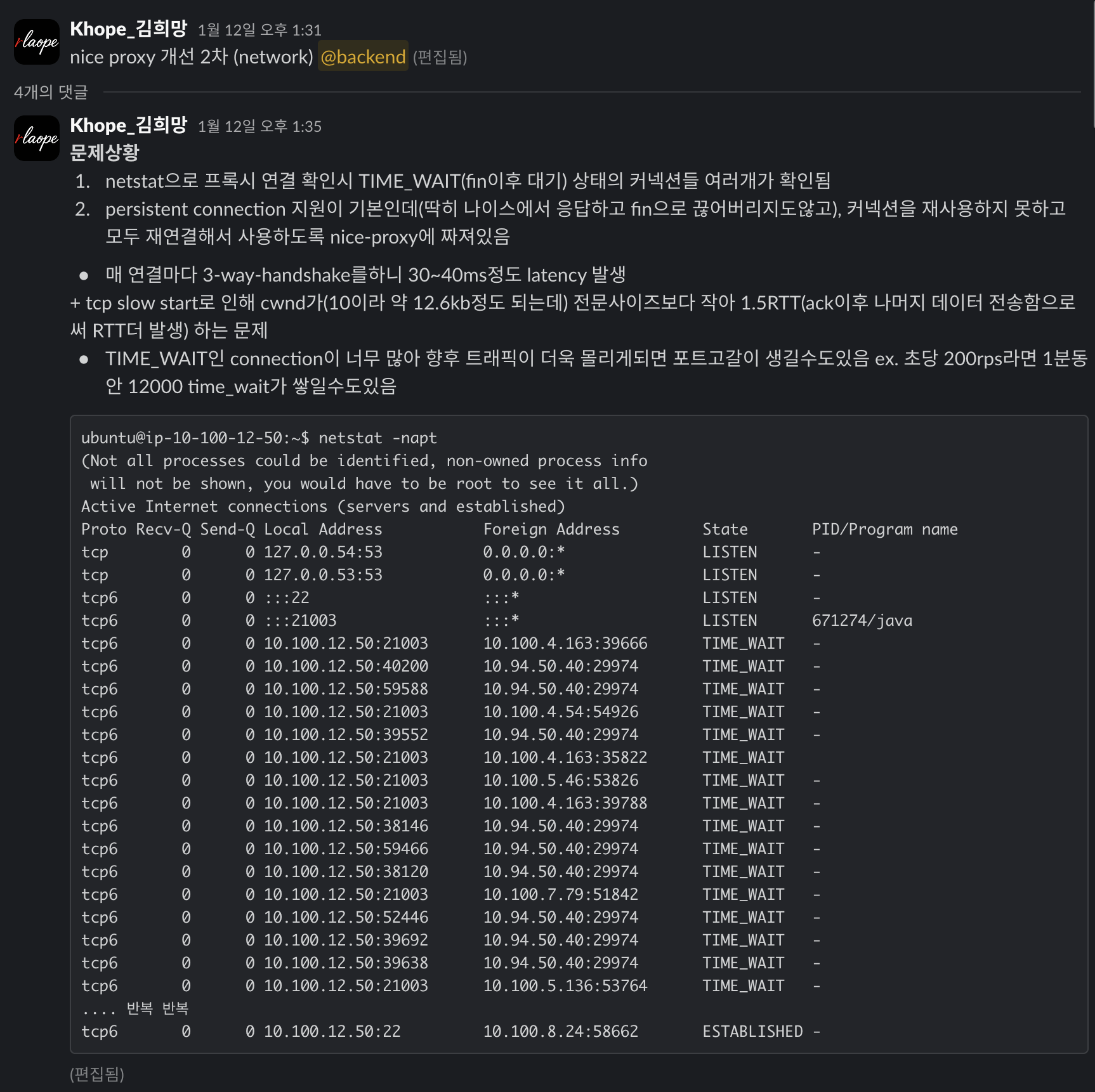
netstat, ss, tcpdump 등으로 커넥션, 패킷 흐름 모니터링 및 별도로 발생하는 레이턴시들 검출했음. 당장은 필요없을 수 있으나, 향후 발전됨에 따라 신경쓰면 좋을 부분들이라 진행함.
- Persistence Connection 방식으로 네티에서 nice session만큼 연결을 맺도록 진행
- Nagle 비활성화로 데이터를 모아 보내는 방식으로 동작하지 않게함. 이로 인해 전문 사이즈가 커서 잘려서 모일때까지 대기하는 현상이 없어짐 (ex. 18kb전문에서 14Kb 전송 이후 그다음 버퍼가 모일때까지 4kb는 대기 같은 현상)
- 그 외에도 jvm observability에 관한 개선에 더욱 기여함 (이는 Netty + 아래 추가될 내용에 연관되어 있으므로 일단 여기선 뺌)
결론적으로 netty event loop 스레드를 단순 증설한다. nice-proxy 서버를 단순히 늘린다. 라는 문제를 재정의하고 실제 존재했던 프록시 서버의 문제들을 파악하고 개선하는 작업 그 이후 observability 개선의 필요성을 느껴 새로 또 발전시킴과 동시에 추가적인 network, tcp 튜닝등으로 레이턴시를 개선함.
JVM Observability & Full GC Hang - Task Server Improve
Summary
As-Is
- JVM Level Observability 부재 (jstat 수동 모니터링만 가능)
- Full GC Hang 감지 시스템 없음 (주말 8시간 무응답)
- MaxRAMPercentage 83.3%로 과다 설정, native memory 영역 부족
- 데이터 전체를 메모리에 올려 처리하는 배치 구조
- HeapDump 옵션 미설정, Kernel OOM Killer로 덤프 유실
To-Be
- JMX Prometheus Exporter로 JVM 메트릭 수집 (GC, Heap, Thread)
- AlertManager 기반 Full GC Hang 실시간 감지 및 알림
- MaxRAMPercentage 60%로 조정, 메모리 8GB → 16GB 증설
- Chunk 기반 데이터 처리로 배치 코드 개선
- HeapDump 옵션 활성화, OOM 방지 체계 구축
월말 정산과 같은 무거운 배치 테스크에서 full gc hang이 걸려 안그래도 무거운 테스크가 무한대로 돌던적이 있었다.
보통 3~4시간이면 끝나는 결산 테스크였는데, 주말에 8시간이 지나도 아무 알림이 없었던 것이였다. 끝났다는.
혹시나 하고 보니 oom은 나지 않았고 로그를 봤을대 20퍼센트정도의 데이터를 처리해놓았었다. 그리고 2시간이 지나고 다시확인해보니 21퍼센트를 처리하고있었고, 그러다 oom이 결국 났다.
배치 시스템의 gc는 parallel gc였고, 최근에 성장세가 높아 처리해야할 데이터가 많아졌다는사실은 알고있었다.
일단 여기서 내가 이상한걸 감지했던것은 왜 OOM이 빨리 안났을까와 + jstat으로 gc로그를 봐서 full gc hang이 걸려있는걸 확인했고 이를 감지할 수 있는 시스템이 있었다면 주말시간을 이렇게 박아넣지 않아도 괜찮았을텐데 라는 생각을 했었다.
가시성
일단 batch system에 jvm level observability가 필요했다 open jdk 8기반 pure java batch system이라 spring boot actuator에서 제공해주는 /metric는 쓸수없었다.
그렇지만 JMX Prometheus Exporter라는 별도의 jar파일을 다른 포트에 띄워 도커파일에 같이 말아 올리게 되면, 같은 컨테이너 다른 포트에 jmx metric을 수집해주는 prometheus exporter를 띄워둘수있다.
java -jar -javaagent:./jmx_prometheus_javaagent.jar=9404:./config.yaml savings-bank-api.jar9404로 띄워두고 jmx_prometheus_javaagent를 initContainer job에 추가해두고 처리하면 바로 같이 띄울수가 있다.
initContainers:
- name: jmx-agent-downloader
image: curlimages/curl:8.6.0
command:
- sh
- -c
- |
echo "[Init] Downloading jmx_prometheus_javaagent.jar..."
mkdir -p /opt/jmx && \
curl -fSL -o /opt/jmx/jmx_prometheus_javaagent.jar \
https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.20.0/jmx_prometheus_javaagent-0.20.0.jar && \
ls -lh /opt/jmx && \
echo "[Init] Done."
volumeMounts:
- name: jmx-exporter-volume
mountPath: /opt/jmx볼륨 마운트해두고 다음과같이 jar를 내려받아서 같이 띄워주면 된다. 물론 프로메테우스가 수집할 수 있도록 포트도 열어두자.
Full GC Hang
일단 JMX Exporter를 쓴다면 아래 두 가지 메트릭이 핵심이다.
- jvm_gc_collection_seconds_sum : GC에 소요된 누적 시간 (가장 중요함)
- jvm_gc_collection_seconds_count : GC 발생 횟수
이때 Minor GC가 아니라 Major(Full) GC만 필터링 해야한다.
- Parallel GC: gc="PS MarkSweep"
- G1GC: gc="G1 Old generation"
자 이제 어떤 메트릭을 쓸지는 알았고 이제 어떤 기준으로 Hang을 판단했는지를 고민해야한다.
우리 시나리오로 예를 들면, 지난 1분동안 GC하느라 예를들어 10초이상 썼는가. (GC Overhead)
시스템이 완전히 멈추지는 않았지만, cpu가 대부분 gc를 점유하고 있는 GC Thrashing 상태를 감지해야한다.
increase(jvm_gc_collection_seconds_sum{gc="PS MarkSweep"}[1m]) > 10
지난 1분동안 10초이상 청소하는데 썼다를 의미하고 16%이상의 cpu 손실을 의미한다. 그리고 월결산 배치기 때문에, 이정도는 너무 짧고 30초 50%정도가 gc를 먹고있다면 gc hang으로 판단하기로 결정했다.
새벽 2시에 도는 배치고 4시간안에 끝나더라도 사실상 주말이면 24시간 안에만 끝내면 되는거고, 50%정도까지 gc쓰는건뭐 우선순위가 더 낮긴했다.
단발성으로 Full GC가 길었던 시간은 중요하지 않다. 이건 배치성 작업이라 성격이 각각의 고객이 늦은 응답을 받아 P99가 박살나는걸 해결하기 위한 목표가 아니였기 때문에 이는 고려하지 않았다.
예외 상황
그리고 추가적으로 하나 더 있는데 JMX Prometheus Exporter에서 metric을 가져오는지라 Full GC의 영향을 JMX Exporter도 받을수도 있다. Full GC가 너무 심각해서 prometheus가 수집하러 갔는데 타임아웃이 나서 데이터를 못가져올수도있다.
그래서 이런 메트릭이 끊기는 현상도 감지해줘야한다.
scrape_duration_seconds{job="my-batch-job"} > 5AlertManager
알림 시스템은 이 지표를 기반으로 AlertManager를 통해 구현한다.
groups:
- name: BatchJobAlerts
rules:
- alert: FullGCHangDetected
# Full GC 시간이 1분간 20초 이상일때
expr: |
increase(jvm_gc_collection_seconds_sum{gc="PS MarkSweep"}[1m]) > 20
for: 1m # 이 상태가 1분간 지속되면 알림 발송
labels:
severity: critical
annotations:
summary: "배치 서버 Full GC Hang 감지 (Instance {{ $labels.instance }})"
description: "현재 Full GC로 인해 시스템이 멈춰있습니다. 힙덤프 확보가 필요할 수 있습니다."이렇게 해서 GC의 Hang을 감지해볼수가 있다.
그 이후 대처
그리고 나서 몇가지 이유를 살펴보았다. 일단 관측성이 없던 배치 시스템에 문제는 해결했으나 그 문제까지 포함하자면 현재 배치시스템에는 다음과 같은 문제들이 있었다.
- 관측성 부족
- Full GC Hang
- OOME
일단 감지는 했지만 해결을 못한 Full GC Hang에 대해서 알아봐야하고 JVM Level에서의 OOM이 아니라 Kernel Level의 OOM Killer가 돌아서 덤프도 남지 않는 문제도 있었다(심지어 덤프 남기는 옵션도 없었음)
일단 Full GC Hang이 난 이유는 간단했다. 해당 결산 배치 테스크가 사용하는 데이터를 단순하게 전부 get해서 메모리에 올려둬 aggregate하는 dto로 매핑한후 data lake에 insert upload하는 방식으로 돌았는데, 이때 올려둔 메모리에 데이터가 많아서 발생한 것이다.
애매하게 OOM이 나지 않고 FullGC가 걸리고 OOM안나고 또 FullGC가 돌고.. 그런식으로
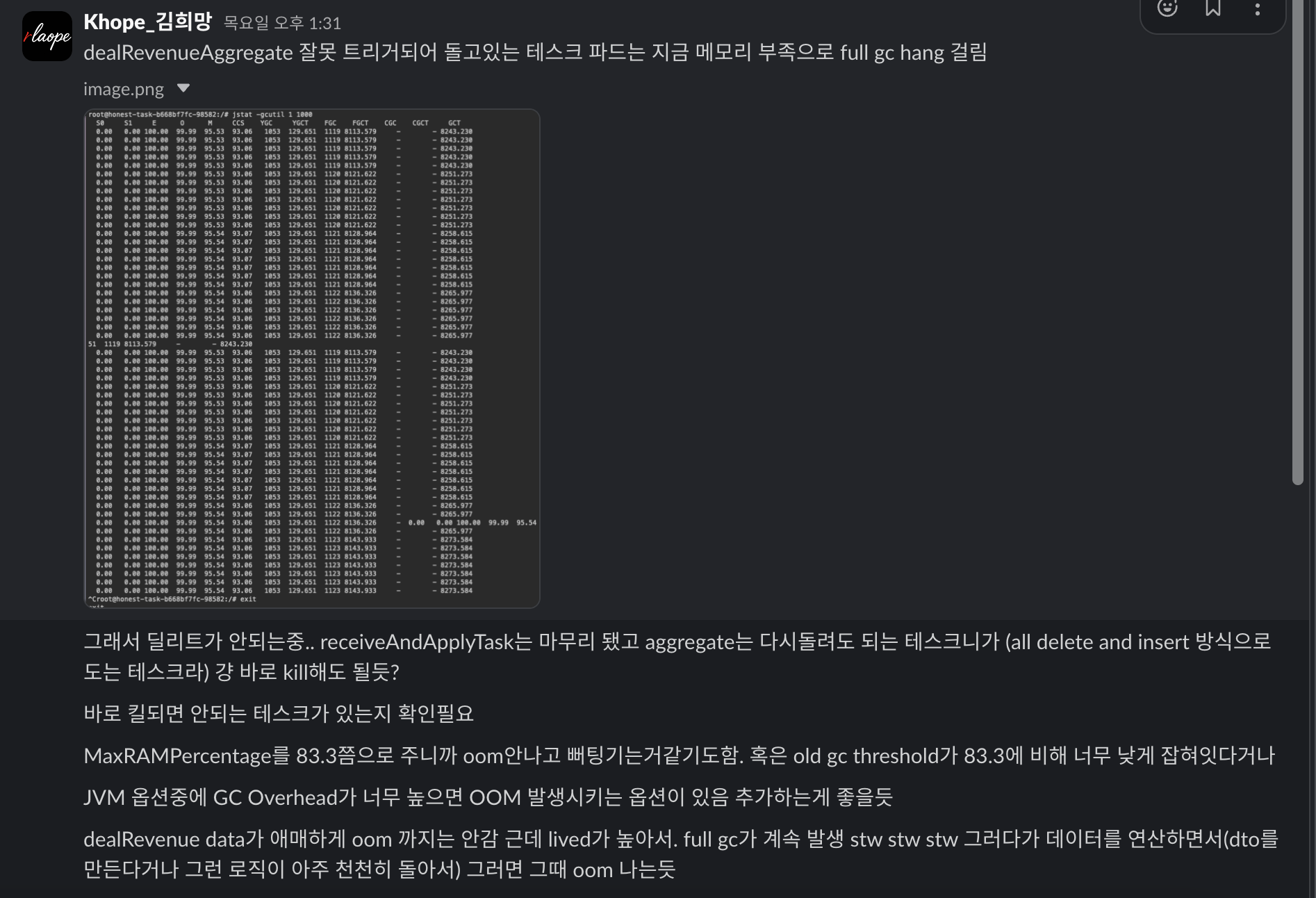
살펴보니까 일단 Full GC의 시간이 일정 시간 이후에(3시간 이후부터) 90퍼센트 이상이 stw로 걸려있었다.
그래서 데이터를 aggregate하는 로직에서 1 2건씩만 돌고 또 stw당하고 근데 메모리에 데이터들 다 살아있고..
Heap Size가 부족한건 당연히 맞았지만 OOM이 바로 발생하지 않은것은 또 별개의 문제라고 생각했다.
확인해보니 MaxRAMPercentage가 83.3% 설정되어 있었다.
과거에 테스크 서버다보니 힙사이즈를 많이 준다는 의사결정이였던거같다. 기본적으로 jvm이 oom을 발생시킬때
gc의 overhead를 감지해서 발생시키는 옵션인 GCOverheadLimit가 존재한다 디폴트로 활성화되어있고 (gc 시간 비율 >= 98%)가 있는데 운이 안좋게도
여기에 걸리기보다 MaxRAMPercentage에서 줘버린 힙의 양때문에 OOME가 먼저 발생해버린것이다.
JVM의 메모리영역은 힙뿐만 아니라 native memory, metaspace, code cache, thread stack등 다양하게 존재하기도 한다. 그래서 사실 힙사이즈가 부족할거같다라는 문제에 대해서는 힙사이즈를 늘리는게 맞지 않았을까 생각이된다. 8GB를 갖고있었는데, 일단은 16GB로 늘려서 그날 테스크는 마무리 시켰다.
Heap Size 튜닝
일단 8GB를 단순하게 늘려주기 이전에, MaxRAMPercentage는 60%로 낮추어주었다 디폴트는 50인데 테스크 서버니까 60으로 두었다. 이러면 코드 캐시나 네이티브 메모리 영역에도 여유가 생겨 최적화레벨을 더 높여볼수도 있지않을까라는 뇌피셜이 있긴하지만 anyway
일단 결과적으로 메모리에 전부 데이터들을 올려서 처리하는 것 자체가 문제였다고 생각한다.
이 월결산 테스크가 어떤 구조냐면 aggregate 데이터를 insert하는 테스크인데, aggregate할 target이 하나가 아니다. (대출자, 투자자, 수수료, 등등등) 데이터들이 많이 있고 각각의 테스크들이 분리되어있고 필요할때 트리거해서 뽑을수있는 기능이다.
근데 월말마다 이런 회계데이터는 필수로 요구된다 그래서 각각의 테스크 코드들을 또 하나로 모은 코드가 바로 이 테스크인것이다.
물론 모든 target 데이터들을 메모리에 올리지는 않는다. 각각의 target 데이터들 모두를 메모리에 올린다. 일단 간단하게 chunk방식으로 올려서 insert하게 해놨다. 별도의 update방식은 존재하지 않으며
데이터 검증하는 task도 존재하고 확인할 수 있으며, 애초에 이 회계데이터를 또 다른 경영팀에서 크로스체크를 하기 때문에 그때 보정작업을 처리하기도 한다.
결론
- JMX Prometheus Exporter로 JVM Observability 개선
- AlertManager로 Full GC Hang 감지
- Full GC Hang 걸린 테스크 코드 개선 및 Heap 튜닝으로 OOME 방지
얻은것은 관측성(메트릭, 알람, heapdump)과 oome 방지, 그리고 task 서버 최적화와 부담스러운 결산작업에 대한 비용이다.
핀테크 엔지니어링, B2B BaaS 모델 Zero to Production
Summary
As-Is
- 연계투자 플랫폼 미존재 (신규 서비스)
- 금융 도메인(대출, 투자, 결제, 결산) 지식 부재 상태에서의 개발 시작
- B2B 외부 기관 연동 경험 없음
- B2C 제휴 채널 트래픽 대응 체계 없음
To-Be
- 연계투자 플랫폼 설계 → 개발 → 출시 → 운영까지 전 과정 수행
- 대출/투자/상품/결제/송금/상환/채권/결산 도메인 전반 이해 및 코드 설계
- 저축은행 중앙회, 은행, CB사 등 B2B 연계 시스템 구축
- Toss/KakaoPay/Finda/Banksalad 등 B2C 트래픽 대응 체계 구축
금융 도메인의 복잡성
어니스트펀드의 연계대출/투자 시스템은 단순히 API 하나 호출해서 끝나는 구조가 아니다.
대출 신청이 들어오면 신용조회(CB사), 심사, 대출 실행, 투자자 매칭, 결제, 송금까지 하나의 플로우 안에서 처리되어야 하고,
이 각각의 단계가 코어뱅킹 시스템(HF), 외부 기관(저축은행 중앙회, 신한은행), CB사(NICE/KCB) 등과 연동되어 있다.
상환 스케줄이 돌면 채권 상태가 바뀌고, 투자자에게 원리금이 분배되며, 연체가 발생하면 또 다른 상태 전이가 생긴다.
결산 시점에는 이 모든 데이터가 회계 기준에 맞게 집계되어야 한다.
즉 대출, 투자, 상품, 결제, 송금, 상환, 채권, 결산이 전부 별개의 도메인처럼 보이지만
실제로는 하나의 거대한 상태 머신 안에서 서로 얽혀 돌아간다.
하나의 상태 전이가 다른 도메인의 상태 전이를 트리거하는 구조다.
코드로 풀어나가기 위한 접근
이런 복잡한 도메인을 코드로 풀어나갈 때 가장 먼저 했던건 상태(state) 설계였다.
대출 하나만 봐도 심사중, 승인, 실행, 상환중, 연체, 완료 같은 상태들이 있고,
각 전이마다 선행 조건과 후속 액션이 다르다. 투자도 마찬가지고.
이걸 if-else로 때려넣으면 한달도 안돼서 아무도 못 읽는 코드가 된다.
그래서 상태 머신을 명확하게 정의하고, 전이 가능한 경로를 코드 레벨에서 제약하는 방식으로 접근했다.
데이터 구조도 원장(ledger) 기반으로 설계되어 있었다. 금융에서는 데이터 정합성이 곧 돈이다.
잔액이 1원이라도 안맞으면 그건 버그가 아니라 사고다.
그래서 코드를 읽을 때도 이 로직이 비즈니스적으로 어떤 영향을 주는지부터 파악하는 습관이 생겼다.
단순히 코드가 동작하는가가 아니라, 이 코드가 틀리면 얼마나 큰 문제가 되는가를 먼저 본다.
여기서 타협의 기준도 생긴다.
돈이 직접 움직이는 결제, 송금, 상환 로직은 절대 타협하지 않는다.
엣지케이스 하나하나 다 커버하고, 멱등성 보장하고, 실패 시 보상 트랜잭션까지 고려한다.
반면 단순 조회나 통계성 데이터는 비즈니스 우선순위에 따라 적절히 타협한다.
모든걸 완벽하게 만들겠다는건 결국 아무것도 제때 못 만들겠다는거랑 같다.
연계투자 플랫폼 Zero to 100
연계투자 플랫폼은 내가 초기 설계부터 참여해서 출시, 운영까지 전 과정을 경험한 서비스다.
제휴 채널(Toss, KakaoPay, Finda, Banksalad 등)로부터 대출 신청이 들어오면,
신용조회 → 심사 → 투자자 매칭 → 대출 실행 → 상환 스케줄 생성까지 하나의 파이프라인으로 처리되는 시스템이다.
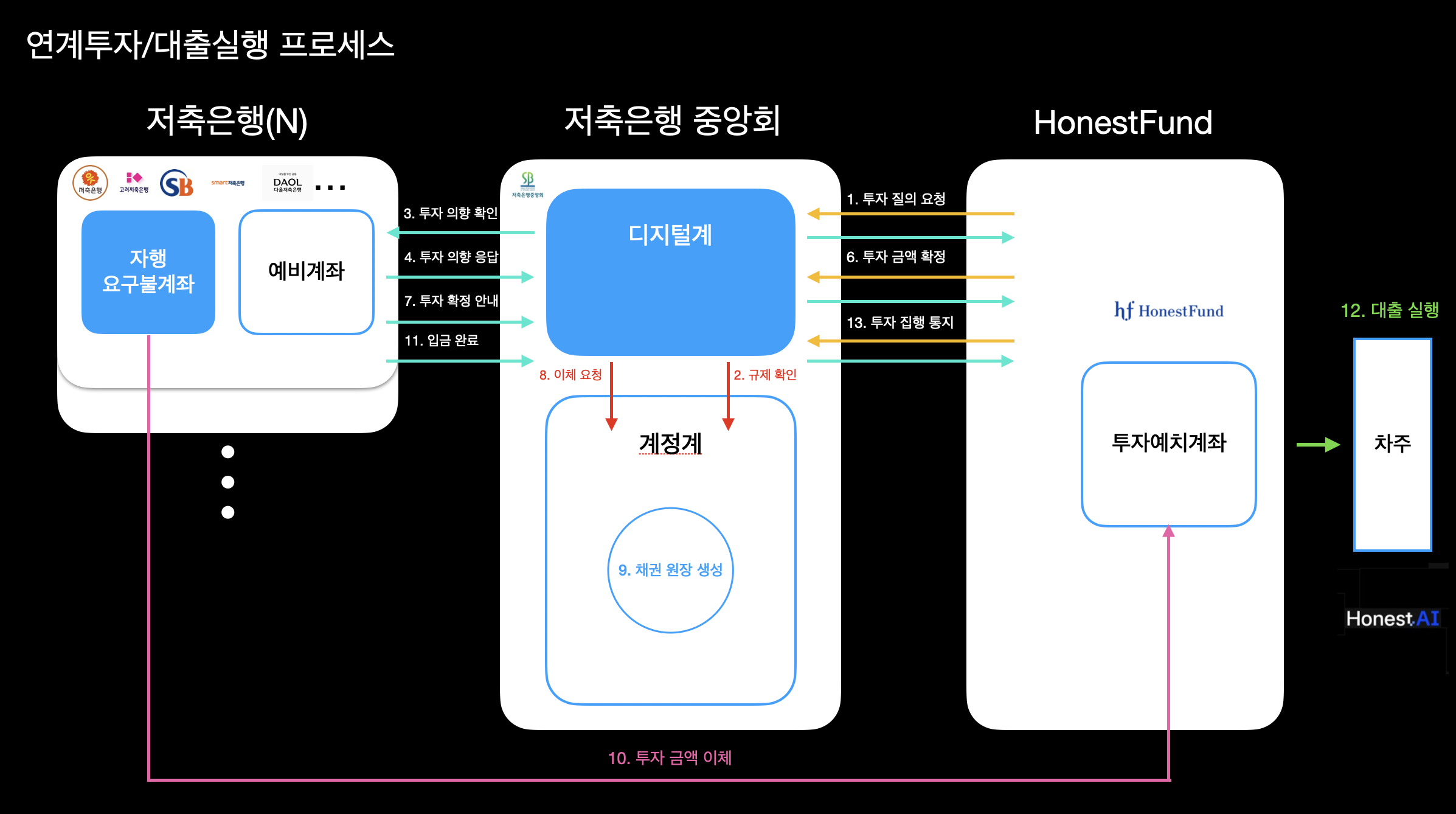
앞서 첫 번째 본문의 아키텍처 차트가 바로 이 시스템의 구조도다.
zero에서 시작했기 때문에 테이블 설계, API 규격, 상태 전이 다이어그램,
에러 핸들링 정책 같은것들을 직접 정의해야 했다.
외부 기관마다 전문 규격이 다르고, 장애 발생 시 어디까지 롤백할건지, 어디서 재시도할건지 같은 정책도 초기에 잡아야 했다.
출시 이후에는 운영 대응이 또 다른 세계였다.
새벽에 배치가 터지거나, 외부 기관 점검 시간에 요청이 밀리거나, 제휴 채널에서 예상치 못한 패턴의 트래픽이 들어오거나.
이런 상황들을 겪으면서 운영 가능한 코드와 그렇지 않은 코드의 차이를 체감했다.
외부 연계 시스템과의 안정성 & 테스트 환경
외부 기관(저축은행 중앙회, 은행, CB사 등)과의 연동은 정해진 규격(전문 통신)으로 동작한다.
안정성이 핵심이고, 장애가 나면 단순히 우리 서비스만 멈추는게 아니라 제휴사 전체에 영향이 간다.
문제는 테스트의 어려움이었다. 외부 기관의 테스트 서버는 항상 열려있는것도 아니고, 응답 패턴도 실 환경과 다를 때가 많다.
그래서 외부 시스템을 똑같이 시뮬레이팅하는 모킹서버를 구축했다.
전문 규격, 응답 시간, 에러 패턴까지 재현할 수 있는 환경을 만들어두니
우리 시스템에 대한 빠른 테스트 검증이 가능해졌다.
이를 통해 외부 시스템과의 개발속도 관련 영향도 결합을 줄일 수 있었다.
장애 감지 알림시스템 & 운영 자동화
입사 초기 도메인을 학습해나가면서 내가 맡지 않은 도메인 영역에 대해서도 관심을 갖고
장애 감지를 위한 알림시스템 구축에 힘썼다.
메뉴얼과 프로세스 등을 확립시켰고, 이로 인해 장애 대응에 관한 비개발자 동료분들의 식별률을 90%까지 끌어올렸다.
기존은 휴리스틱하게 보면 30%채도 안되었다.
프로세스를 추가해두어 메뉴얼하게 코드가 처리하거나, 인간이 UI로 처리하거나,
쿼리를 치거나 등에 대한 기능화를 진행했다.
그리고 어느정도 검증이 끝난 반복작업들은 자동화시켰다.
수십개가 넘는 운영 메뉴얼에 들어있던 수기작업들을 자동화시킨것이다.
깨달음
금융 도메인에서 일하면서 가장 크게 깨달은건 커뮤니케이션이다.
PO와는 비즈니스 요구사항을 기술 제약과 맞춰서 조율해야 하고,
경영팀과는 결산/회계 기준을 코드로 어떻게 반영할건지 합의해야 한다.
외부 기관과는 전문 규격 변경이나 점검 일정을 사전에 조율해야 하고.
코드만 잘 짜면 되는게 아니라, 이해관계자들과의 소통이 프로젝트 성패를 좌우한다는걸 체감했다.
그리고 도메인 이해 없이는 좋은 코드를 짤 수 없다는것도 확실히 느꼈다.
왜 이 상태가 필요한지, 왜 이 필드가 nullable인지, 왜 이 로직이 동기로 처리되어야 하는지.
도메인을 모르면 이런 판단을 코드 레벨에서 내릴 수가 없다.
결국 엔지니어가 도메인을 깊이 이해할수록 더 좋은 설계가 나온다.
- 대출/투자/결제/송금/상환/채권/결산 등 금융 도메인 전반 이해
- 연계투자 플랫폼 Zero to Production 전 과정 경험 (설계 → 개발 → 출시 → 운영)
- 외부 연계 시스템 모킹서버 구축으로 테스트 검증 환경 확보 및 개발속도 결합 해소
- 비즈니스 임팩트 기반 코드 분석 및 타협 기준 수립
- 도메인 이해 + 커뮤니케이션이 좋은 설계의 전제조건이라는 깨달음